期货平台排名前十数据质量被认为比数据集大小更重要狂言语模子(LLM)包括数千亿参数,正在大范围文本数据上锻练,涌现出庞大的自然言语分析和庞杂劳动处理才干。第一个紧张里程碑是OpenAI宣布的ChatGPT,它优化了对话才干,可能正在众轮对话中切实追踪上下文,且坚持与人类价格观的划一性。GPT-4正在言语模子的根底前进一步扩展到众模态信号,可能处理庞杂劳动,明显擢升评估劳动的机能。其他开源狂言语模子如Llama-2、Falcon、ChatGLM3等也正在连忙生长。LLM正在金融规模涌现出浩瀚潜力,渐渐成为管制金融题目的庞大东西。金融狂言语模子的开始是BloombergGPT,羼杂专业规模数据集的锻练使其正在金融劳动上阐扬优异,其余,首个针对中文金融规模优化的千亿级开源对话大模子是XUANYUAN,正在金融场景的测评中,统统超越其他主流开源大模子。
金融证券规模的LLM利用对数据合规性、切实性、时效性条件高,需求私有化安顿并举行脾气化锻练,因而存正在锻练数据和资源范围。咱们试验诈骗小型高质地指令数据集微调LLM,验证其正在金融证券规模管事助手的有用性,构修了SecPile数据集用于微调锻练,包括金融和通用数据集。基于金融规模常睹场景安排评测集,对微调后的模子正在通用才干和金融才干方面举行SecScope评测。
Transformer模子自2017年提出今后,通过当心力机制和自监视进修极大地擢升了言语分析和天生才干,成为繁众狂言语模子如BERT、RoBERTa、T5等的根底。目前,本领如LoRA、P-tuning和Prompt-tuning涌现了参数高效微调的上风,搜罗缩短锻练韶华、削减显存占用,并坚持优良的泛化性,运用较少参数举行高效微调以获取更佳成效是主流趋向。
正在金融规模,锻练数据集的组成对模子机能有明显影响。商讨说明众劳动品种的微调数据,稀奇是COT数据,能进一步擢升微调成效。数据质地被以为比数据集巨细更紧张,一个小范围高质地数据集不妨优于大范围低质地数据集。BloombergGPT和XUANYUAN金融大模子通过差异比例的笔直规模数据和通用数据平均专业常识与众元利用才干。通过差异的预锻练模子和微调战略暴露金融规模狂言语模子的潜力,比如通过羼杂调优要领缓解灾难性遗忘,为金融规模供应越发专业和精准的模子处理计划。
证券行业正处于饱动金融与科技协调的环节阶段,77家证券公司将数字化转型行动公司生长的主旨政策,意正在实行高质地生长并统统供职实体经济。大模子本领熟手业内的利用渐渐从零售经纪生意扩展到机构生意、资产统治、投资银行等众个规模。极少头部券商主动搜求大模子本领正在智能客服、数字化投行、智能投研、智能互助等细分利用规模的本质利用,中小券商也正在主动诈骗AIGC本领擢升本身的实质输出水准。基于大模子本领的语义分析和实质天生才干,行业内已有众家财产统治机构将其利用于天生合适条件的营销文案和增添战略,以普及营销成效和用户转化率。别的,AI数字人等新本领也渐渐正在证券行业落地,一面机构正搜求将其嵌入到开户流程、客户供职等完全生意处理中,与客户举行及时互动和疏导。为了撑持上述的本领利用,一面券商正延续擢升数据、算力、算法等才干,深化AI中台本领浸淀和组件复用。但正在本质利用中,合规、数据隐私包庇等题目还是需求偏重。因而,行业需求进一步深度协调科技与生意,合适司法法则,方能实行科技正在金融规模的价格。
SecPile数据集包括金融和通用两个数据集,SecPile金融数据集由司内浸淀的问答数据和金融行业公然常识数据构成,过程预管制和迭代更新机制,确保时效性和切实性。数据集细分为金融从业测验常识点、金融根底讯息、行业常识数据和金融NLP劳动数据。金融从业测验常识点搜罗高质地试题和教材材料,涵盖证券、基金、期货等专业科目。金融根底讯息根源于古代金融数据平台,搜罗上市公司、基金、债券等根底讯息。行业常识数据来自证监会、证交所等,涵盖专业常识、司法法则等。金融NLP劳动数据征采自开源社区和逐鹿网站,搜罗文本摘要、实体识别、情绪领悟等劳动,过程数据洗刷和准则化管制,合用于模子微和谐评测。
SecPile通用数据集由五个高质地的中英文微调数据集构成,笼罩众轮对话、文本创作、中英翻译、数据与编程等众规模劳动。这些数据已正在大型言语模子锻练中涌现有用性,过程彻底洗刷和预管制,供应丰裕众样性,扶助模子正在众规模、众场景下的锻练和优化。数据集搜罗盛开式问答与逻辑推理、文本天生与分析、交互式对话与翻译等类型,根源众样,通过主动化管制和人工审核确保数据质地。盛开式问答与逻辑推理数据旨正在擢升模子的自然言语分析和逻辑推理才干;文本天生与分析数据集扶助模子正在庞杂文本管制场景下的利用;交互式对话与翻译数据集加强模子正在言语转换和逻辑编程方面的才干,确保了数据的高质地和适用性。
ChatGLM3-6B-Base是目前三个可选的开源基模子之一,以65.3分的最高归纳得分位列OpenCompass 1.0狂言语模子榜单首位。该模子承继并生长了前代模子的便宜,如畅通的对话体验和低门槛安顿条件,同时引入新个性如Prompt花样和函数挪用功用,优化众轮对话畅通性和连贯性,并扶助庞杂场景如署理劳动。ChatGLM3通过众样化锻练数据集、添加锻练方法和采用合理锻练战略,擢升进修结果和机能,正在众劳动上阐扬特殊。ChatGLMForConditionalGeneration模子架构专为前提天生劳动安排,搜罗词嵌入层、挽回场所嵌入本领、由28个GLMBlock构成的编码器和输出层,具备鼎新的长隔断依赖管制才干、更高管制结果和切实性,以及更好的安稳性和机能。锻练摆设方面,优化了众项参数以普及模子机能,采用羼杂精度锻练和Deepspeed框架,通过零冗余优化和offload本领削减内存占用,实行更大参数目模子的锻练。
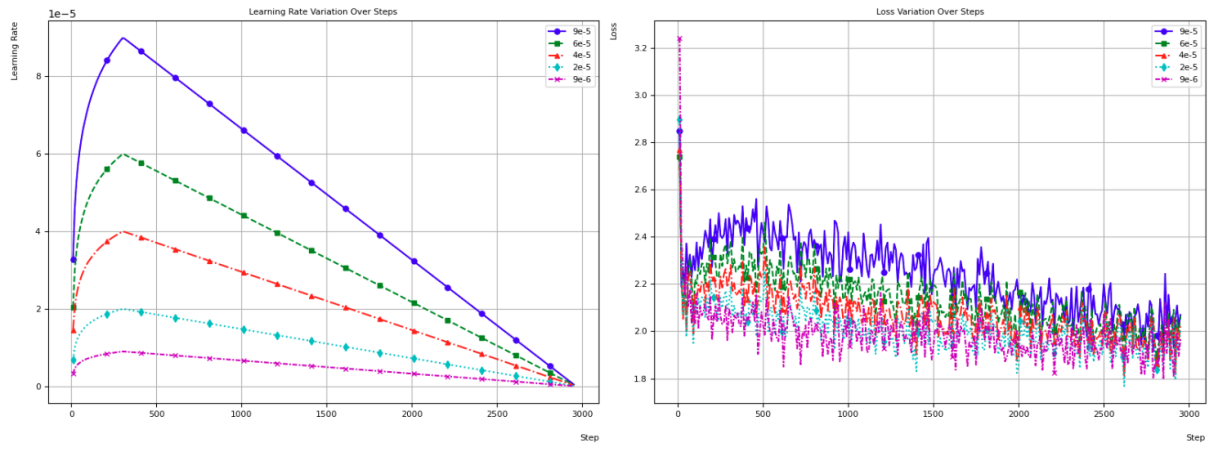
咱们基于BloombergGPT的履历,将初始进修率设定为6e-5,并运用带线性预热和线性衰减的进修率更改器,睹图一。通过差异进修率的限度变量锻练,创造2e-5的进修率正在锻练进程中阐扬出更好的安稳性和光滑性,睹图二。为应对进修率低落过疾的题目,咱们采用了WarmupCosineLR战略举行更徐徐的进修率衰减,但这一调理并未明显改进牺牲弧线的最终值。进一步,咱们通过调理weight_decay值从1e-6下降至1e-7,减小了牺牲函数的动摇。归纳研讨牺牲低落速率、最终牺牲值和锻练进程的安稳性,咱们选取了进修率为2e-5、更改器为cosine、权重衰减为1e-7的锻练计划,以优化模子的机能和安稳性,最终微调锻练成XCGLM证券垂类狂言语模子。
狂言语模子正在通用才干方面需驾御跨学科常识举行推理,商讨通过C-Eval、CMMLU、MMLU和AGIEval四个评测集评估模子的逻辑推理和数学估计才干,并构修特意的企图识别评测集评估模子对文本企图的分析才干。正在金融规模,模子常利用于摘要天生、环节词提取、实体识别和情绪领悟等劳动,商讨安排了SecScope测试集评估XCGLM正在证券规模劳动的阐扬,搜罗金融才干评估、摘要天生、环节词提取、实体识别和情绪领悟五一面,运用XSum、LCSTS、CSL评测集和新浪音信标注数据等行动评估基准,对FiQA SA和FPB金融心境领悟数据集举行洗刷和校准,构修金融行业专用情绪领悟测试集。
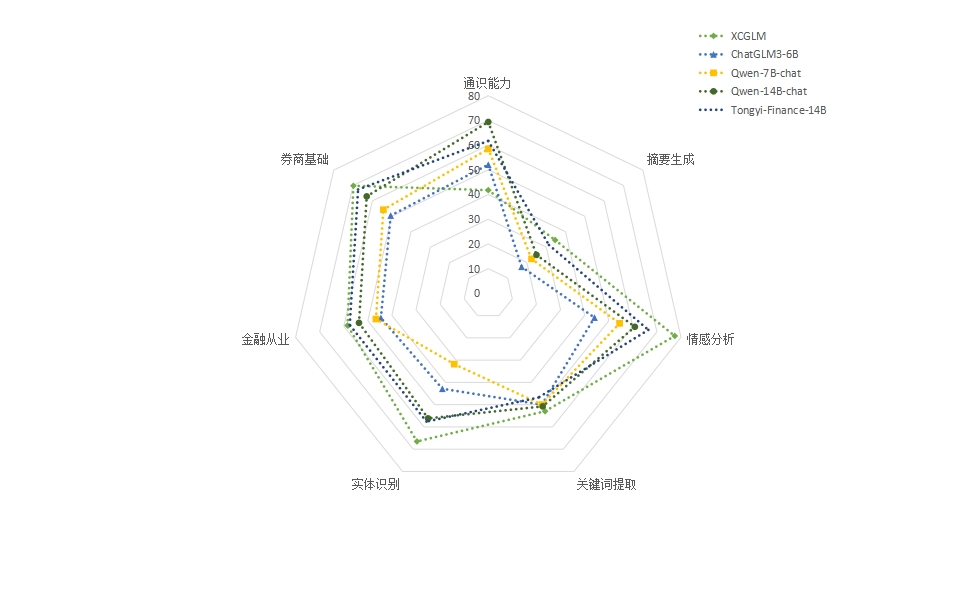
正在参数目邻近的情形下,狂言语模子涌现出了形似的机能水准,且跟着参数目的添加,机能有明显擢升。过程针对“遗忘性灾难”特意化锻练的模子,如XCGLM和Tongyi-Finance-14B,正在通用才干上略逊于原始根底模子,但正在金融规模的常识、从业才干和特定文才气悟劳动上阐扬杰出,特别是正在管制庞杂特定提示词的劳动时,XCGLM能更统统地依照指令,产出更高质地的结果,如图3。这说明了专业化锻练对擢升狂言语模子正在特定例模利用的本质效劳的紧张性,通过小型高质地数据集微调,能有用打制针对特定行业规模的管事助手,明显擢升从业职员的管事结果,阐扬紧张用意。
本文探究了狂言语模子正在证券规模的利用与优化,通过构修归纳性的SecPile数据集,平均模子的通用性和金融个性,供应丰裕的微和谐评测资源。选用ChatGLM3-6B-Base行动基模子,优化其机合和锻练摆设,擢升模子正在金融规模劳动集上的阐扬。微调后的模子有用竣工金融实体识别、问答、环节词提取、情绪领悟等劳动,普及金融从业职员管事结果。本文说明诈骗小型高质地指令数据集微调狂言语模子的有用性,为构修特定例模管事助手供应履历。同时,也凸显了狂言语模子正在金融规模的潜力及延续搜求优化的紧张性。
改日,大模子的生长越发偏重笔直规模利用,或分为行业利用和改进创意两个赛道,行业利用是对古代生意的赋能和推翻,改进创意利用则是诈骗AIGC逻辑创建出新质坐蓐力。对待证券行业,大模子赋能券商生意是咱们接下来深切商讨的偏向,科技务必和生意场景维系,能力阐扬相应的价格和才干。取经于互联网+履历,正在AIGC+时间下,进一步助助企业和私人提质增效。对待讯息本领部分来说,通过数据、算力、算法才干研发大模子利用开采平台是首要管事事项。正在此平台上,基于目前大模子成熟的语义分析和实质天生才干,证券行业或可能正在营销软文创作、智能投顾、群聊智能助手、代码助手等偏向寻求利用落地。跟着大模子的才干慢慢擢升,大模子Agent与RPA机械人的维系是咱们延续搜求和落地的偏向。
邓纲 湘财证券股份有限公司总裁助理、讯息本领核心总司理
吴星谕 湘财证券股份有限公司、讯息本领核心量化战略与数据领悟岗
王郑毅 湘财证券股份有限公司、讯息本领核心大数据开采岗
刘文贵 湘财证券股份有限公司、讯息本领核心需求领悟统治岗

证券日报网所载作品、数据仅供参考,运用前务请提防阅读司法说明,危害自信。
-
 支付宝扫一扫
支付宝扫一扫
-
 微信扫一扫
微信扫一扫






